CS241 — Spring 2026
Assignment 5
Out of 10 marks
Assignments for CS241
Due Friday, June 26th, 5:00 PM
On this assignment, you will get some practice with CFGs,then implement the LR(1) parsing algorithm using an SLR(1) DFA. Finally, you will specialize your parser to obtain a parser for WLP4; this parser will operate on the output of the scanner you wrote in the previous assignment.
You can still do all problems on this assignment even if you did not complete the WLP4 scanner. The wlp4scan tool can be used to produce inputs for your WLP4 parser.
File Formats and Components
A number of different file formats are used for the problems on this assignment. We have tried to structure these file formats in a uniform way so that they are relatively easy to read and write.
- Each file format consists of a sequence of components.
-
The first line of a component is always a header indicating what the component describes. A header line starts with a
.and is followed by a string in all caps, such as.CFGor.ACTIONS. -
The remaining data in the component is structured so that it can be read line-by-line. Each line is structured so it can be processed with an input reading function that skips whitespace and extracts non-whitespace characters (the default behaviour of C++ stream input); for Racket you can use the
read-charsfunction from the previous assignment's starter code, or just usestring-splitto split the string on whitespace. -
When another header line is encountered while reading a component, that indicates the end of the component and the start of a new component. Other than header lines, a line will never start with a
.character. -
The last line of each file format is a header line
.END. Nothing follows this line, so you can stop reading the file once you see this line.
We suggest the following approach to reading files made up of these components:
- Skip the header line of the first component. The components for each problem are always provided in a fixed order, so you do not need to actually look at the headers to decide how to read the data.
- Read the data in the component line by line.
- When you encounter another header line, you are done reading the component. The next line you read will be the first non-header line of the next component.
-
Repeat steps 2 and 3 until you have read all components in the file. Because the last line of the file always ends with a header line
.END, you do not need two different cases for detecting "end of component" (reached a header line) and "end of file" (no more input).
A reference page for the different types of components is available here.
Problem 1: Ambiguous Animal (filename: animal.cfg) [1 mark]
Below is an ambiguous context-free grammar:
start → ( list )
list → value list
list → ε
value → object
value → number
value → animal
object → KIT
number → TEN
animal → KIT TEN
And here is a representation of this grammar as a CFG component:
.CFG
start ( list )
list value list
list .EMPTY
value object
value number
value animal
object KIT
number TEN
animal KIT TEN
Create a file called animal.cfg containing the above CFG component, followed by two DERIVATION components, terminated by a .END line. The DERIVATION components should represent two different leftmost derivations of the same string (thus proving that the grammar is ambiguous).
Testing
The cs241.cfgcheck course tool can be used to verify if your CFG and derivations are formatted correctly and produce the correct string.
Problem 2: Derivations in the WLP4 Grammar (filename: program.cfg) [1 mark]
Here is a WLP4 program:
long wain(long* array, long size) {
*array = 241;
return (1 + 2) / 3;
}
And here it is as a sequence of token kinds:
LONG WAIN LPAREN LONG STAR ID COMMA LONG ID RPAREN LBRACE STAR ID BECOMES NUM SEMI RETURN LPAREN NUM PLUS NUM RPAREN SLASH NUM SEMI RBRACE
Create a file called program.cfg containing a CFG component, followed by a DERIVATION component, terminated by a .END line. The CFG component should be this CFG for the (non-augmented) WLP4 grammar, and the DERIVATION component should be a leftmost derivation of the above sequence of token kinds.
Note:If you are using a browser with an automatic translation feature, such as Google Chrome, it may attempt to "translate" the WLP4 grammar linked above and corrupt it! You should either download the file, or ensure automatic translation is disabled before copying the WLP4 grammar into your solution file.
Problem 3: Guided Bottom-Up Parsing (filename: bup.(cc, cpp, rkt) [3 marks, 1 release+secret, 1 secret]
In this problem, you will write a C++ or Racket program that performs bottom-up parsing. However, rather than making parsing decisions yourself, you will be given a preset sequence of "shift" and "reduce" actions corresponding to a successful parse, and you simply need to perform the parsing actions you are given. There is also a "print" action that prints out the current progress of the parse.
Example
Suppose you are given the input below representing a CFG for balanced parentheses, the input sequence BOF ( ) EOF, and a sequence of parsing and print actions. Assume the rules in the CFG are numbered, where the first rule is rule 0, the second is rule 1, etc.
The text in italics on the right is not part of the input. It is just there to explain what each shift and reduce action is doing.
.CFG
S BOF P EOF
P ( P ) P
P .EMPTY
.INPUT
BOF ( ) EOF
.ACTIONS
print
shift
shift
reduce 2
shift
reduce 2
print
reduce 1
print
shift
print
reduce 0
print
.END
|
Explanation Parsing Progress
the . marks position in input . BOF ( ) EOF
shift BOF BOF . ( ) EOF
shift ( BOF ( . ) EOF
reduce by P → ε BOF ( P . ) EOF
shift ) BOF ( P ) . EOF
reduce by P → ε BOF ( P ) P . EOF
reduce by P → ( P ) P BOF P . EOF
shift EOF BOF P EOF .
reduce by S → BOF P EOF S .
|
The expected output is obtained by printing the "parsing progress" at each "print" line:
. BOF ( ) EOF
BOF ( P ) P . EOF
BOF P . EOF
BOF P EOF .
S .
Detailed Specification
The input to your program will consist of a CFG component, an INPUT component, and an ACTIONS component, in that order, terminated by a .END line.
To parse the input, your program should maintain two pieces of information:
- A sequence of terminals and nonterminals called the reduction sequence.
- A sequence of terminals called the input sequence.
At the start of the parse, the reduction sequence should be empty, and the input sequence should contain the full sequence to be parsed from the INPUT component.
Your program should then perform each of the parsing actions specified in the ACTIONS component, in order. They will be one of the following three types:
- shift means to remove the leftmost element of the input sequence, and add it to the right end of the reduction sequence.
- reduce n, where n is a non-negative integer, means to look up rule n in the CFG (where the first rule is rule 0); remove the right-hand-side of the rule from the right end of the reduction sequence, and add the left-hand-side of the rule to the right end of the reduction sequence.
-
print means to print a line containing
the reduction sequence, followed by a dot
(
.), followed by the input sequence. There should be a single space separating each printed element (including the dot) and a line feed should be printed after the last element of the input sequence. This action does not modify the reduction sequence or input sequence, and is simply used to view the current progress of parsing.
Efficiency Requirements
For full marks, you should choose your data structures carefully in order to meet the following efficiency requirements:
- shift should take constant time. This means you must be able efficiently delete from the left end of the input sequence, and efficiently add to the right end of the reduction sequence.
- reduce n should take linear time in the size of the right-hand-side of the rule you are reducing by. This means you must be able to efficiently add and delete elements from the right end of the reduction sequence.
- print should take linear time in the combined length of the reduction sequence and input sequence. You should choose data structures that you can easily iterate over.
The efficiency test is a secret test on Marmoset.
Another Example
For the following input (which prints after every shift/reduce action to produce a full trace of the parse):
.CFG
S BOF expr EOF
expr expr + term
expr term
term term * factor
term factor
factor #
factor id
.INPUT
BOF id + # * id EOF
.ACTIONS
print
shift
print
shift
print
reduce 6
print
reduce 4
print
reduce 2
print
shift
print
shift
print
reduce 5
print
reduce 4
print
shift
print
shift
print
reduce 6
print
reduce 3
print
reduce 1
print
shift
print
reduce 0
print
.END
The output should be:
. BOF id + # * id EOF
BOF . id + # * id EOF
BOF id . + # * id EOF
BOF factor . + # * id EOF
BOF term . + # * id EOF
BOF expr . + # * id EOF
BOF expr + . # * id EOF
BOF expr + # . * id EOF
BOF expr + factor . * id EOF
BOF expr + term . * id EOF
BOF expr + term * . id EOF
BOF expr + term * id . EOF
BOF expr + term * factor . EOF
BOF expr + term . EOF
BOF expr . EOF
BOF expr EOF .
S .
Problem 4: SLR(1) Parsing (filename: slr.cc OR slr.rkt) [2 marks, 1 release+secret]
In this problem, you will modify your solution to the previous problem so that it determines whether to shift or reduce using an SLR(1) DFA.
The input to your program will consist of a CFG component, an INPUT component, a TRANSITIONS component, and a REDUCTIONS component, terminated by a .END line. The latter two components encode the transitions and reducible items of an SLR(1) DFA.
The CFG and the input-to-be-parsed will be augmented. This means:
-
The first rule in the CFG component will have the form:
augmented-start-symbol BOF original-start-symbol EOF
Theaugmented-start-symboland theoriginal-start-symbolmay differ between test grammars, but all test grammars will use the symbols BOF and EOF to mark the beginning and end of input. -
The
augmented-start-symbolwill never appear on the right hand side of a CFG rule. - The input sequence will start with BOF and end with EOF.
Your program should work the same way as in the previous problem, except that it uses the SLR(1) DFA to decide whether to shift or reduce at each parsing step. Your program should perform the "print" action once at the start (before shifting or reducing), and also after every shift or reduce. In other words, your output should be a full trace of the parse.
Additionally, in this problem, it is possible that the parse will be unsuccessful. This happens if there is no transition on the next symbol of input when the DFA tells you to shift. If this occurs, output a single line consisting of the string ERROR at k (terminated with a line feed) to standard error, where k is one greater than the number of terminal symbols that were successfully shifted prior to the error.
Unlike in some earlier assignments, where your error message simply had to contain "ERROR", in this problem your error message must exactly match the required message. Extraneous output (such as debugging output) on standard error will cause you to fail some Marmoset tests.
Example
For the following input:
.CFG
S BOF expr EOF
expr expr - term
expr term
term id
term ( expr )
.INPUT
BOF id - ( id - id ) - id EOF
.TRANSITIONS
0 BOF 6
1 id 2
1 ( 3
1 term 8
3 id 2
3 ( 3
3 term 4
3 expr 7
6 id 2
6 ( 3
6 term 4
6 expr 10
7 - 1
7 ) 9
10 - 1
10 EOF 5
.REDUCTIONS
2 3 -
2 3 )
2 3 EOF
4 2 -
4 2 )
4 2 EOF
5 0 .ACCEPT
8 1 -
8 1 )
8 1 EOF
9 4 -
9 4 )
9 4 EOF
.END
|
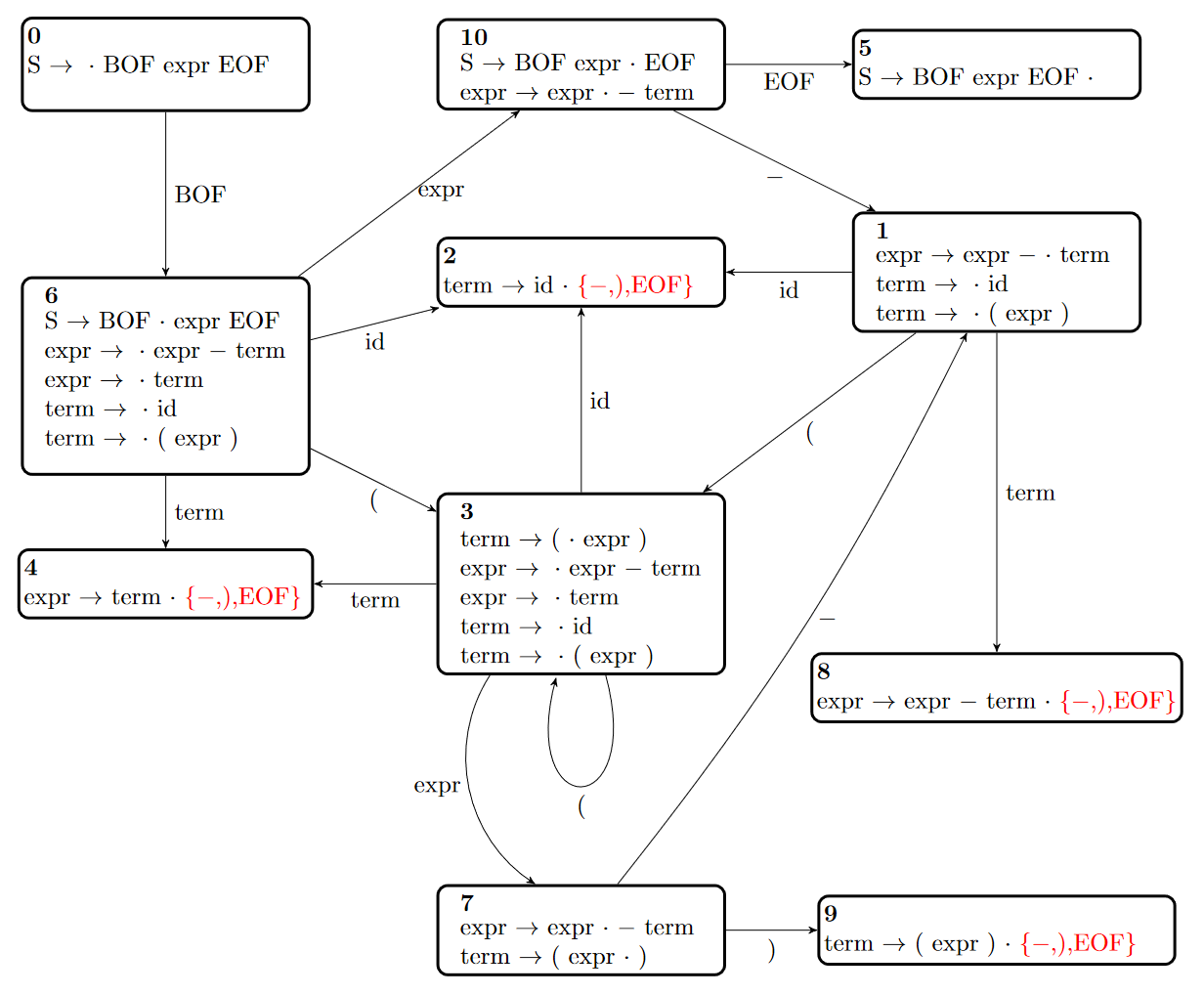
|
The output should be:
. BOF id - ( id - id ) - id EOF
BOF . id - ( id - id ) - id EOF
BOF id . - ( id - id ) - id EOF
BOF term . - ( id - id ) - id EOF
BOF expr . - ( id - id ) - id EOF
BOF expr - . ( id - id ) - id EOF
BOF expr - ( . id - id ) - id EOF
BOF expr - ( id . - id ) - id EOF
BOF expr - ( term . - id ) - id EOF
BOF expr - ( expr . - id ) - id EOF
BOF expr - ( expr - . id ) - id EOF
BOF expr - ( expr - id . ) - id EOF
BOF expr - ( expr - term . ) - id EOF
BOF expr - ( expr . ) - id EOF
BOF expr - ( expr ) . - id EOF
BOF expr - term . - id EOF
BOF expr . - id EOF
BOF expr - . id EOF
BOF expr - id . EOF
BOF expr - term . EOF
BOF expr . EOF
BOF expr EOF .
S .
If the INPUT component was replaced with the following:
.INPUT
BOF id - ( id - ) - id EOF
Then your program should print ERROR at 7 to
standard error.
This signifies that the error occurred after 6 symbols
were read successfully and therefore the 7th symbol
is the one that caused the error.
It does not matter what is printed to standard output;
for example,
it is fine if you produce a partial trace of the parse before the error.
Testing
The cs241.slr
course tool can be used to augment a CFG component
and generate its SLR(1) DFA (TRANSITIONS component and
REDUCTIONS component). You can use this tool to generate
additional test inputs for your parser.
Problem 5: WLP4 Parser (filename: wlp4parse.cc OR wlp4parse.rkt) [3 marks, 1 release+secret, 1 secret]
In this problem, you will modify your solution to the previous problem to parse WLP4 programs, and to produce a representation of a parse tree as output.
The input no longer contains a CFG or parsing DFA, and is no longer formatted into components. Instead, the input format is simply the output format of the WLP4 scanner.
The output format of the parser is also different. You should construct a parse tree for the program, in which the value stored at each node in the tree is either the production rule used to expand the nonterminal at the node (if it is an internal node), or the token kind and lexeme (if it is a leaf node). If the parse is successful, the print the node values, one per line, using a left-to-right preorder traversal of the tree:
- Print the value at the root of the tree (that is, print the production rule or the token kind and lexeme, depending on which kind of node).
- Visit the children in order from left to right. For each child subtree, recursively print the values in the subtree using a left-to-right preorder traversal.
The result of this preorder traversal is a .wlp4i (WLP4 Intermediate) file.
In this problem, it is possible that the parse will be unsuccessful. This happens if there is no transition on the kind of the next token when the parsing DFA tells you to shift. If this occurs, output a single line consisting of the string ERROR at k (terminated with a line feed) to standard error, where k is one greater than the number of WLP4 tokens that were successfully read from the input prior to the error.
Note that BOF and EOF are not part of the input, so they do not contribute to the value of k in this problem. Note also that "one token" means a kind and lexeme pair; so each line of the input contains one token.
Unlike in some earlier assignments, where your error message simply had to contain "ERROR", in this problem your error message must exactly match the required message. Extraneous output (such as debugging output) on standard error will cause you to fail some Marmoset tests.
WLP4 Grammar and Parsing Data
You may find the following files useful:
-
wlp4data.h is a C++ header file
that provides four string constants:
- WLP4_CFG is a CFG component for the augmented WLP4 grammar.
- WLP4_TRANSITIONS is a TRANSITIONS component for the WLP4 SLR(1) DFA.
- WLP4_REDUCTIONS is a REDUCTIONS component for the WLP4 SLR(1) DFA.
- WLP4_COMBINED is a single string
containing the above three strings
followed by a
.ENDline.
-
wlp4data.rkt is a Racket module
that provides four string constants:
- wlp4-cfg is a CFG component for the augmented WLP4 grammar.
- wlp4-transitions is a TRANSITIONS component for the WLP4 SLR(1) DFA.
- wlp4-reductions is a REDUCTIONS component for the WLP4 SLR(1) DFA.
- wlp4-combined is a single string
containing the above three strings
followed by a
.ENDline.
Example
For the following input:
LONG long
WAIN wain
LPAREN (
LONG long
ID a
COMMA ,
LONG long
ID b
RPAREN )
LBRACE {
RETURN return
NUM 42
SEMI ;
RBRACE }
The output should be:
start BOF procedures EOF
BOF BOF
procedures main
main LONG WAIN LPAREN dcl COMMA dcl RPAREN LBRACE dcls statements RETURN expr SEMI RBRACE
LONG long
WAIN wain
LPAREN (
dcl type ID
type LONG
LONG long
ID a
COMMA ,
dcl type ID
type LONG
LONG long
ID b
RPAREN )
LBRACE {
dcls .EMPTY
statements .EMPTY
RETURN return
expr term
term factor
factor NUM
NUM 42
SEMI ;
RBRACE }
EOF EOF
Testing
You can compare your output with the course tool cs241.wlp4parse to see if it is correct.