CS 779 Final Project
Robert Suderman20259802
Core Project
The core project was an implementation of Loop Subdivision both on CPU and GPU using OpenCL. These models would be viewed using OpenGL in a wireframe view. OBJ files would be loaded into a mesh datatype which could be subsequently subdivided. To demonstrate the speed of subdivison each frame the mesh would be subdivided to its selected level.
- CPU Based Loop Subdivision
- GPU Loop Subdivsion Using OpenCL
- Wireframe viewer
- OBJ File Loader
Extras
As additional extras, I implementaed OBJ file loading along with computing the surface normals so that the models would be viewable in a separate mesh viewer. Furthermore, I pipelined the GPU memory model between subdivision levels so that only a single transfer is required for subdivision and viewing while on the GPU.
- OBJ File Write
- Normal Computation
- Optimization
- Pipelined Memory Mode
- Triangularization of non triangular meshes
Implementing
Implementing the CPU Loop subdivison and winged data structure was straightforward. As complex data structures on GPU tend to have poor performance, I opted for a simpler series of structures. Each structure only had a fixed number members with placeholders for when the value did not exist. When transfering the implementation to GPU, the existing parallelized solution was quickly converted into OpenCL kernels with minor modifications due to OpenCL C language restrictions.
The only task requiring significant change was updating old vertex positions. As parallel threads cannot update the sum of adjacents for a vertex at the same time, each sum must be performed independantly. A list of adjacent vertices to each vertex is stored, allowing these vertices to be updated independantly. While the model is loaded the initial adjacency list is determined and updated at the end of each subdivision.
Extras
Implementing a pipelined memory mode was reasonably quick and required on demand transfer if the subdivsion method changes (transferring to and from the GPU method as necessary). It also required implementing OpenGL transfer code which would transfer to mapped OpenGL buffers.
Due to the quantity of data, many optimizations using constant and local memory exceed the memory restrictions. Memory operations were grouped to coalesce as many reads/writes as possible.
Implementing Normal computation provided issues in the parallel model as the average of each vertex normal must be computed. Using the adjacency list, the vertex adjacent to each individual vertex could be found, however the this list it was not possible to determine orientation. In order to ensure normal contributed positively to its direction (and ensure each points in the same relative direction) the first normal was taken as the front face and the rest were computed from this resulting normal. While this did produce a face normal, in some cases the normal would occur in the opposite direction. Setting the adjacency ordering s.t. it occurs in the correcting ordering would produce a correctly oriented ordering, this ordering was not yet determined.
Results
2.2 Ghz i7 with ATI Radeon M 6750
Performance results varied significantly on the mesh and number of subdivision levels being used. Small meshes with few subdivsions did cause lower speeds due to driver communication time and insufficient work to saturate the GPU cores, larger sample problems produced better performance results. Maximum speedup doubled the processing rate on the GPU.
Lessons Learned
When designing a GPU based subdivision algorithm, there are a number of things to consider. Ensure you data structure is deisgned from the ground up to opimize memory access for GPU. While the CPU's cash can handle most memory operations on the CPU subdivsion scheme, a significant amount of performance is lost to uncoelesced writes. This also means data should be ordered in a white to maxmimize linear reads, otherwise poorly organized meshes can severely impace performance speed.
Implementing a viewing system in OpenGL for both wireframe and filled polygons is straight forward, implementing VBO shared drawing is unintuitive and opposite direction normals are not determined. While one would assumed the normals could be oriented using the face direction, the front face back face system when implementing systems like this are frustrating (orienting the face vertices and determining the correct normal direction can be problematic).
While loop subdivision is quite simple for subdision, preserving sharp edges are difficult. Implementing a scaling factor on edge "sharpness" would allow sharp edges to remain sharp edges (this is most obvious on the bust).
Overall it is possible to improve performance by sending the model to the GPU and minimize data transfer, there are only a few reasons to perform this. If the system has a significantly more powerful GPU than CPU, then transfering the model on the GPU rather than CPU makes sense. Furthermore, if the CPU is already heavily loaded with work offloading the subdivision task to the GPU makes sense. In general, with inconsistent results, the benefits are inssuficient to justify however future improvements to the data structure and more optimizations may provide better results.
Examples
Bust Example


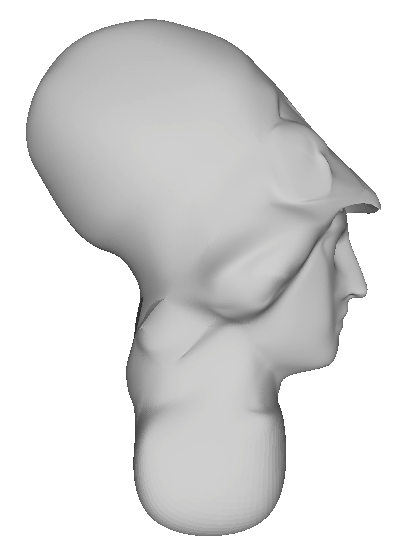
- CPU Based Loop Subdivision
- GPU Loop Subdivsion Using OpenCL
- Wireframe viewer
- OBJ File Loader
- OBJ File Write
- Normal Computation
- Optimization
- Pipelined Memory Mode
- Triangularization of non triangular meshes
Implementing
Implementing the CPU Loop subdivison and winged data structure was straightforward. As complex data structures on GPU tend to have poor performance, I opted for a simpler series of structures. Each structure only had a fixed number members with placeholders for when the value did not exist. When transfering the implementation to GPU, the existing parallelized solution was quickly converted into OpenCL kernels with minor modifications due to OpenCL C language restrictions.
The only task requiring significant change was updating old vertex positions. As parallel threads cannot update the sum of adjacents for a vertex at the same time, each sum must be performed independantly. A list of adjacent vertices to each vertex is stored, allowing these vertices to be updated independantly. While the model is loaded the initial adjacency list is determined and updated at the end of each subdivision.
Extras
Implementing a pipelined memory mode was reasonably quick and required on demand transfer if the subdivsion method changes (transferring to and from the GPU method as necessary). It also required implementing OpenGL transfer code which would transfer to mapped OpenGL buffers.
Due to the quantity of data, many optimizations using constant and local memory exceed the memory restrictions. Memory operations were grouped to coalesce as many reads/writes as possible.
Implementing Normal computation provided issues in the parallel model as the average of each vertex normal must be computed. Using the adjacency list, the vertex adjacent to each individual vertex could be found, however the this list it was not possible to determine orientation. In order to ensure normal contributed positively to its direction (and ensure each points in the same relative direction) the first normal was taken as the front face and the rest were computed from this resulting normal. While this did produce a face normal, in some cases the normal would occur in the opposite direction. Setting the adjacency ordering s.t. it occurs in the correcting ordering would produce a correctly oriented ordering, this ordering was not yet determined.
Results
2.2 Ghz i7 with ATI Radeon M 6750
Performance results varied significantly on the mesh and number of subdivision levels being used. Small meshes with few subdivsions did cause lower speeds due to driver communication time and insufficient work to saturate the GPU cores, larger sample problems produced better performance results. Maximum speedup doubled the processing rate on the GPU.
Lessons Learned
When designing a GPU based subdivision algorithm, there are a number of things to consider. Ensure you data structure is deisgned from the ground up to opimize memory access for GPU. While the CPU's cash can handle most memory operations on the CPU subdivsion scheme, a significant amount of performance is lost to uncoelesced writes. This also means data should be ordered in a white to maxmimize linear reads, otherwise poorly organized meshes can severely impace performance speed.
Implementing a viewing system in OpenGL for both wireframe and filled polygons is straight forward, implementing VBO shared drawing is unintuitive and opposite direction normals are not determined. While one would assumed the normals could be oriented using the face direction, the front face back face system when implementing systems like this are frustrating (orienting the face vertices and determining the correct normal direction can be problematic).
While loop subdivision is quite simple for subdision, preserving sharp edges are difficult. Implementing a scaling factor on edge "sharpness" would allow sharp edges to remain sharp edges (this is most obvious on the bust).
Overall it is possible to improve performance by sending the model to the GPU and minimize data transfer, there are only a few reasons to perform this. If the system has a significantly more powerful GPU than CPU, then transfering the model on the GPU rather than CPU makes sense. Furthermore, if the CPU is already heavily loaded with work offloading the subdivision task to the GPU makes sense. In general, with inconsistent results, the benefits are inssuficient to justify however future improvements to the data structure and more optimizations may provide better results.
Examples
Bust Example
Implementing the CPU Loop subdivison and winged data structure was straightforward. As complex data structures on GPU tend to have poor performance, I opted for a simpler series of structures. Each structure only had a fixed number members with placeholders for when the value did not exist. When transfering the implementation to GPU, the existing parallelized solution was quickly converted into OpenCL kernels with minor modifications due to OpenCL C language restrictions.
The only task requiring significant change was updating old vertex positions. As parallel threads cannot update the sum of adjacents for a vertex at the same time, each sum must be performed independantly. A list of adjacent vertices to each vertex is stored, allowing these vertices to be updated independantly. While the model is loaded the initial adjacency list is determined and updated at the end of each subdivision.
Implementing a pipelined memory mode was reasonably quick and required on demand transfer if the subdivsion method changes (transferring to and from the GPU method as necessary). It also required implementing OpenGL transfer code which would transfer to mapped OpenGL buffers.
Due to the quantity of data, many optimizations using constant and local memory exceed the memory restrictions. Memory operations were grouped to coalesce as many reads/writes as possible.
Implementing Normal computation provided issues in the parallel model as the average of each vertex normal must be computed. Using the adjacency list, the vertex adjacent to each individual vertex could be found, however the this list it was not possible to determine orientation. In order to ensure normal contributed positively to its direction (and ensure each points in the same relative direction) the first normal was taken as the front face and the rest were computed from this resulting normal. While this did produce a face normal, in some cases the normal would occur in the opposite direction. Setting the adjacency ordering s.t. it occurs in the correcting ordering would produce a correctly oriented ordering, this ordering was not yet determined.
Results
2.2 Ghz i7 with ATI Radeon M 6750
Performance results varied significantly on the mesh and number of subdivision levels being used. Small meshes with few subdivsions did cause lower speeds due to driver communication time and insufficient work to saturate the GPU cores, larger sample problems produced better performance results. Maximum speedup doubled the processing rate on the GPU.
Lessons Learned
When designing a GPU based subdivision algorithm, there are a number of things to consider. Ensure you data structure is deisgned from the ground up to opimize memory access for GPU. While the CPU's cash can handle most memory operations on the CPU subdivsion scheme, a significant amount of performance is lost to uncoelesced writes. This also means data should be ordered in a white to maxmimize linear reads, otherwise poorly organized meshes can severely impace performance speed.
Implementing a viewing system in OpenGL for both wireframe and filled polygons is straight forward, implementing VBO shared drawing is unintuitive and opposite direction normals are not determined. While one would assumed the normals could be oriented using the face direction, the front face back face system when implementing systems like this are frustrating (orienting the face vertices and determining the correct normal direction can be problematic).
While loop subdivision is quite simple for subdision, preserving sharp edges are difficult. Implementing a scaling factor on edge "sharpness" would allow sharp edges to remain sharp edges (this is most obvious on the bust).
Overall it is possible to improve performance by sending the model to the GPU and minimize data transfer, there are only a few reasons to perform this. If the system has a significantly more powerful GPU than CPU, then transfering the model on the GPU rather than CPU makes sense. Furthermore, if the CPU is already heavily loaded with work offloading the subdivision task to the GPU makes sense. In general, with inconsistent results, the benefits are inssuficient to justify however future improvements to the data structure and more optimizations may provide better results.
Examples
Bust Example
Performance results varied significantly on the mesh and number of subdivision levels being used. Small meshes with few subdivsions did cause lower speeds due to driver communication time and insufficient work to saturate the GPU cores, larger sample problems produced better performance results. Maximum speedup doubled the processing rate on the GPU.
When designing a GPU based subdivision algorithm, there are a number of things to consider. Ensure you data structure is deisgned from the ground up to opimize memory access for GPU. While the CPU's cash can handle most memory operations on the CPU subdivsion scheme, a significant amount of performance is lost to uncoelesced writes. This also means data should be ordered in a white to maxmimize linear reads, otherwise poorly organized meshes can severely impace performance speed.
Implementing a viewing system in OpenGL for both wireframe and filled polygons is straight forward, implementing VBO shared drawing is unintuitive and opposite direction normals are not determined. While one would assumed the normals could be oriented using the face direction, the front face back face system when implementing systems like this are frustrating (orienting the face vertices and determining the correct normal direction can be problematic).
While loop subdivision is quite simple for subdision, preserving sharp edges are difficult. Implementing a scaling factor on edge "sharpness" would allow sharp edges to remain sharp edges (this is most obvious on the bust).
Overall it is possible to improve performance by sending the model to the GPU and minimize data transfer, there are only a few reasons to perform this. If the system has a significantly more powerful GPU than CPU, then transfering the model on the GPU rather than CPU makes sense. Furthermore, if the CPU is already heavily loaded with work offloading the subdivision task to the GPU makes sense. In general, with inconsistent results, the benefits are inssuficient to justify however future improvements to the data structure and more optimizations may provide better results.
Examples
Bust Example
| Number Subdivisions | CPU Runtime (sec) | GPU Runtime (sec) |
| 1 | 0.001 | 0.001 |
| 2 | 0.003 | 0.003 |
| 3 | 0.011 | 0.018 |
| 4 | 0.053 | 0.039 |
Cube Example



| Number Subdivisions | CPU Runtime (sec) | GPU Runtime (sec) |
| 1 | 0.000 | 0.001 |
| 2 | 0.000 | 0.001 |
| 3 | 0.000 | 0.002 |
| 4 | 0.001 | 0.003 |
Teapot Example



| Number Subdivisions | CPU Runtime (sec) | GPU Runtime (sec) |
| 1 | 0.001 | 0.001 |
| 2 | 0.003 | 0.003 |
| 3 | 0.010 | 0.008 |
| 4 | 0.047 | 0.030 |
Elf Example



| Number Subdivisions | CPU Runtime (sec) | GPU Runtime (sec) |
| 1 | 0.006 | 0.009 |
| 2 | 0.032 | 0.017 |
| 3 | 0.145 | 0.084 |
| 4 | 0.670 | 0.774 |
| Number Subdivisions | CPU Runtime (sec) | GPU Runtime (sec) |
| 1 | 0.003 | 0.012 |
| 2 | 0.015 | 0.015 |
| 3 | 0.072 | 0.065 |
| 4 | 0.322 | 0.267 |