Software (CS451/651 only)
Data-Intensive Distributed Computing (Winter 2024)
Bespin
Bespin is a software library that contains reference implementations of "big data" algorithms in MapReduce and Spark. It provides sample code for many of the algorithms we'll be discussing in class and also provides starting points for the assignments. You'll want to familiarize yourself with the library.
Single-Node Hadoop: Linux Student CS Environment
A single-node Hadoop cluster (also called "local" mode) comes
pre-configured in the linux.student.cs.uwaterloo.ca
environment. We will ensure that everything works correctly in this
environment.
TL;DR. Just set up your environment as follows (in bash; adapt accordingly for your shell of choice):
export PATH=/usr/lib/jvm/java-8-openjdk-amd64/jre/bin:/u3/cs451/packages/spark/bin:/u3/cs451/packages/hadoop/bin:/u3/cs451/packages/maven/bin:/u3/cs451/packages/scala/bin:$PATH export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
Note that we do not advise you to add the above lines to
your shell config file (e.g., .bash_profile), but rather
to set up your environment explicitly every time you log
in. The reason for this is to reduce the possibility of conflicts when
you start using the Datasci cluster (see below).
Alternative: Put those two lines in a file called setup-cs451. Then all you have to do when you log in is:
source setup-cs451
It's easier than copy & pasting those two lines.every time.
More adventerous alternative: put the following code into your .bashrc file:
if [ $HOSTNAME != 'datasci' ]
then
export PATH=/usr/lib/jvm/java-8-openjdk-amd64/jre/bin:/u3/cs451/packages/spark/bin:/u3/cs451/packages/hadoop/bin:/u3/cs451/packages/maven/bin:/u3/cs451/packages/scala/bin:$PATH
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
fi
The if block will prevent it from running on datasci, so it should be safe!
Details. For the course we need Java, Scala, Hadoop, Spark,
and Maven. Java is already available in the default user environment
(but we need to point to the right version). The rest of the packages
are installed in /u3/cs451/packages/. The
directories scala, hadoop, spark,
and maven are actually symlinks to specific
versions. This is so that we can transparently change the links to
point to different versions if necessary without affecting downstream
users. Currently, the versions are:
- Java: 1.8.0
- Scala: 2.11.8
- Hadoop: 3.0.3
- Spark: 2.3.1
- Maven: 3.3.9
Single-Node Hadoop: Personal Install
In addition to using the single-node Hadoop cluster
on linux.student.cs.uwaterloo.ca, you may wish to install
all necessary software packages locally on your own machine. We
provide basic installation instructions here, but the course staff
cannot provide technical support due to the size of the class and the
idiosyncrasies of individual systems. We will be responsible for
making sure everything works properly in the Linux Student CS
Environment (above), but can only offer limited help with your own system. It's pretty straight forward in Ubuntu (whether running natively or using WSL under Windows).
Both Hadoop and Spark work fine on Mac OS X and Linux, but may be difficult to get working on Windows (I very strongly suggest that you use WSL, where it's easy). Note that to run Hadoop and Spark on your local machine comfortably, you'll need at least 4 GB memory and plenty of disk space (at least 10 GB).
You'll also need Java (Must use JDK 1.8), Scala (must use Scala 2.11.8 EXACTLY since Maven is picky about versions), and Maven (any reasonably recent version).
The versions of the packages installed
on linux.student.cs.uwaterloo.ca are as follows:
Download the above packages, unpack the tarball, add their
respective bin/ directories to your path (and your shell
config), and you should be go to go.
Alternatively, you can also install the various packages using a
package manager, e.g., apt-get, MacPorts, etc. However,
make sure you get the right version.
Distributed Hadoop Cluster: Datasci
In addition to running "toy" Hadoop on a single node (which obviously defeats the point of a distributed framework), we're going to using the school's modest Hadoop teaching cluster called Datasci.
Warning
If you've added setup scripts for other courses in the past, you might have to remove that from your .bashrc, .bash_profile, .profile, or wherever else you put them! In particular, CS348's setup is breaking people's $PATH variable and leaving them unable to do anything on datasci! (CS246 setup fails to display a cow fortune, which is probably nothing to worry about unless you really wanted your cow fortune). If you have datasci problems, and say you have never modified your profile files, but you, in fact, have done so, I will make this face: 😞Accounts are already set up for students enrolled in the course. You should be able to log into the cluster as follows:
ssh -D 1080 <your userid>@datasci.cs.uwaterloo.ca
If you're using PuTTY then you'll find this option under "Connection" > "SSH" > "Tunnels"
Set "source port" to 1080, leave destination blank, and select "dynamic", then click "add". You should see "D1080" added to the list of forwarded ports. Don't forget to go back to "Sessions" and save your changes.
NOTE: The Datasci cluster does not accept password logins (at least, not from off-campus). You must configure a public/private keypair. You can find directions here: MFCF - Creating SSH keys. Datasci shares the file system with student.cs so adding to your authorized_keys file on student.cs will also add it to datasci.
If you're using PuTTY on Windows, the program to use is called "PuTTYGen". Save the private key somewhere, and copy public key text shown into "~/.ssh/authorized_keys". Unlike under Linux, putty does not default to trying private keys, you have to configure this manually. Under "Connection" > "SSH" > "Auth", enter the location of your private key in the box labeled "Private key for authentication".
The -D option specifies dynamic port forwarding, which
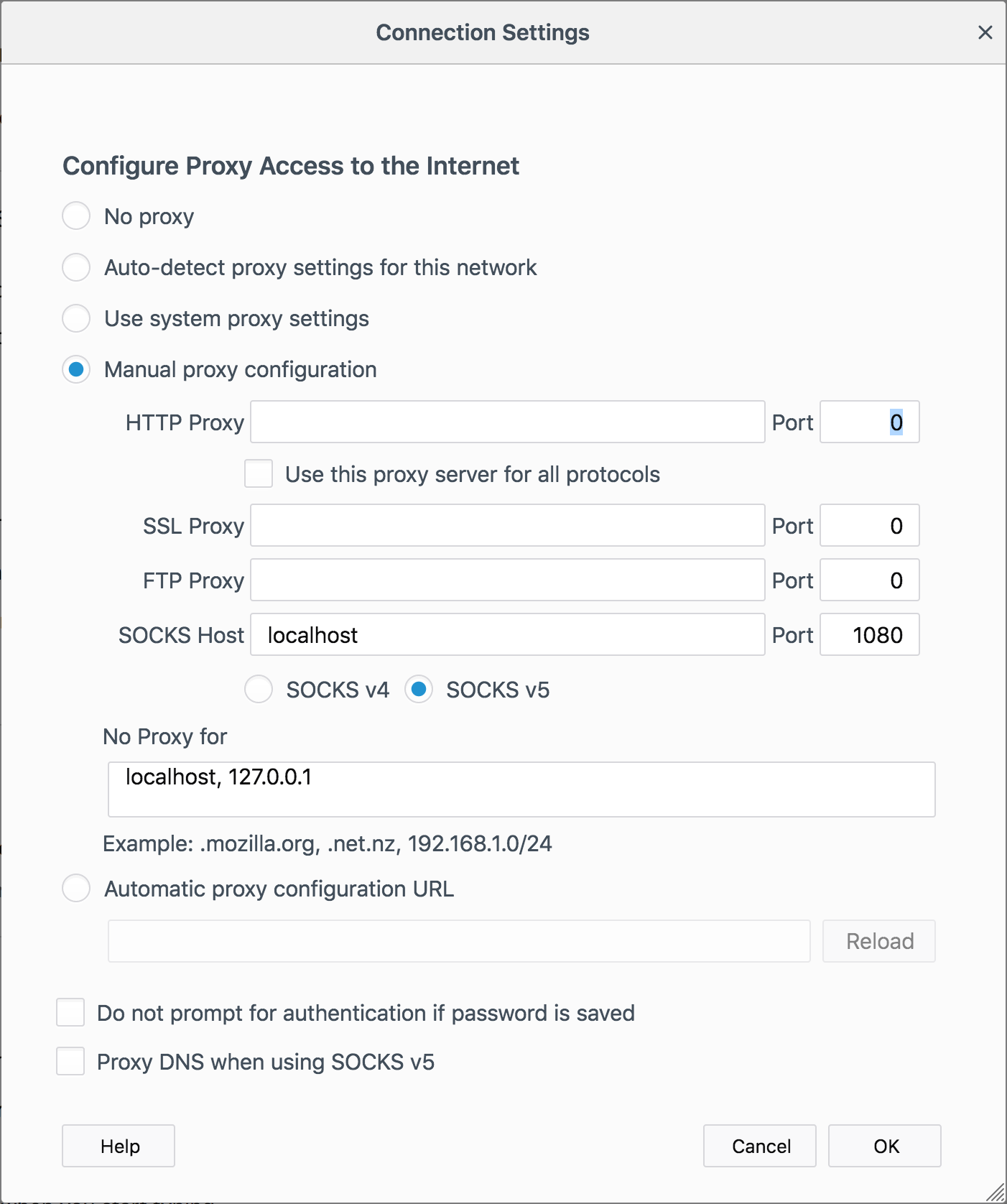
you'll need for accessing the Hadoop UIs through a SOCKS proxy. The
simplest approach is via the Firefox browser: go to preferences and
access "Network Proxy" settings: your settings should look
something like this. You
should then be able to access the Resource Manager (RM) webapp
at http://datasci.datasci-domain.cs.uwaterloo.ca:8088/cluster.
It's important that you get the proxy working, because the RM webapp
is the primary point of access for examining and debugging jobs on the
cluster.
{kind=link}
Note that some ISPs, routers, and/or security software may block the DNS lookup for datasci-domain.cs.uwaterloo.ca. The reason is tha this is a public domain name but we've got it pointed to a private IP range.
If you get an error "We're having trouble finding that site." that means the DNS lookup failed. Try instead connecting to http://10.10.154.191:8088/cluster.
NOTE: Do not set up the environment in Datasci. The path is already set.
HINT
With Firefox, the proxy setup limits your ability to access other sites; turn off the proxy once you're done with the cluster. One helpful tip while working on assignments is to access the cluster webapp in Firefox, and use another browser for accessing other sites. There are many other equivalent ways to set up your proxy (different OSes, different browsers, etc.) as well as alternative workflows. Feel free to share tips, experiences, etc. on Piazza.
Dan has a hint here: There's a firefox plugin called FoxyProxy that gives you a lot more control over proxy settings.